이번에는 Colab으로 자신만의 스테이블 디퓨젼 모델(이미지 생성이 가장 쉬울 것이라 판단되어 이미지를 생성해보도록 하겠다.)을 만들어서 이미지를 생성해보겠다.
#modules load
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
from PIL import Image
from torchvision.models import vgg19
import math
import torch_xla
import torch_xla.core.xla_model as xm
import clip
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#device = xm.xla_device()우선 필요한 모듈들을 불러온다.
모델의 아키텍처는 다음과 같다
.
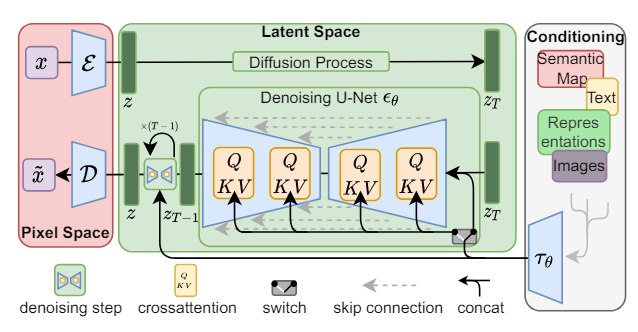
우선적으로 attention block을 만들어준다.
class AttentionBlock(nn.Module):
def __init__(self,group,out_channels,num_heads):
super(AttentionBlock, self).__init__()
self.attention_norm = nn.GroupNorm(group, out_channels)
self.attention = nn.MultiheadAttention(out_channels,num_heads,batch_first=True) #??
def forward(self,x):
#Attention Block
batch_size, channels, h, w = x.shape
in_attn=x.reshape(batch_size,channels, h*w)
in_attn = self.attention_norm(in_attn)
in_attn = in_attn.transpose(1,2)
out_attn, _ = self.attention(in_attn,in_attn,in_attn)
out_attn = out_attn.transpose(1,2).reshape(batch_size,channels,h,w)
return out_attn참고로 stable diffusion은 latent diffusion 아키텍쳐를 상속받고 있으므로 latent space로 mapping할 encoder와 원래대로 복원할 decoder도 만들어서 따로 학습시켜야한다.
encoder은 다음과 같다.
class Block(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,bias=False):
super(Block, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.SiLU(),
nn.AvgPool2d(2),
)
def forward(self, x):
x = self.block1(x)
return x
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.block1=Block(3,8) #//2
self.block2=Block(8,16) #//4
self.block3=Block(16,32) #//8
self.block4=Block(32,64) #//16
self.getmu=nn.Conv2d(64,64,kernel_size=1,stride=1,padding=0,bias=False)
self.logvar=nn.Conv2d(64,64,kernel_size=1,stride=1,padding=0,bias=False)
self.sig=nn.Sigmoid()
def forward(self,x):
x=self.block1(x)
x=self.block2(x)
x=self.block3(x)
x=self.block4(x)
mu = self.sig(self.getmu(x))
logvar = self.sig(self.logvar(x))
std = torch.exp(0.5 * logvar)
z=mu+std*torch.randn_like(std)
return z, mu, logvar
decoder은 다음과 같다.
class BlockD(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,bias=False):
super(BlockD, self).__init__()
self.block1 = nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.SiLU(),
nn.UpsamplingBilinear2d(scale_factor=2),
)
def forward(self, x):
x = self.block1(x)
return x
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.block1 = BlockD(64, 32) #*2
self.block2 = BlockD(32, 16) #*4
self.block3 = BlockD(16, 8) #*8
self.block4 = BlockD(8, 3) #*16
self.block5 = nn.ConvTranspose2d(3, 3,1,1,0, bias=False)
self.tanh=nn.Tanh()
def forward(self,x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x=self.tanh(x)
return xencoder과 decoder을 연결하여 VAE모델을 만든다.
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.encoder=Encoder()
self.decoder=Decoder()
def forward(self,x):
z,mu,logvar=self.encoder(x)
output=self.decoder(z)
return output,mu,logvar
그 다음으로 디퓨전모델의 시간적인 부분을 제어하기 위한 타임 스케줄러를 만들어 준다.
class TimeSchdule:
def __init__(self):
self.betas=torch.linspace(0.0001,0.02,1000).to(device)
self.alphas = 1-self.betas
self.alpha_cum_prod = torch.cumprod(self.alphas,dim=0)
self.sqrt_alpha_cum_prod = torch.sqrt(self.alpha_cum_prod)
self.one_minus_alpha_cum_prod = 1.-self.alpha_cum_prod
self.sqrt_one_minus_alpha_cum_prod = torch.sqrt(1.-self.alpha_cum_prod)
def add_noise(self,original,noise,t):
original_shape = original.shape
batch_size=original_shape[0]
sqrt_alpha_cum_prod=self.sqrt_alpha_cum_prod[t].reshape(batch_size) #batchsize
sqrt_one_minus_alpha_cum_prod=self.sqrt_one_minus_alpha_cum_prod[t].reshape(batch_size)
for _ in range(len(original_shape)-1):
sqrt_alpha_cum_prod = sqrt_alpha_cum_prod.unsqueeze(-1) #batchsize,1,1,1
sqrt_one_minus_alpha_cum_prod=sqrt_one_minus_alpha_cum_prod.unsqueeze(-1)
return sqrt_alpha_cum_prod*original + sqrt_one_minus_alpha_cum_prod*noise
def sample_prev_timestep(self,xt,noise_pred,t):
x0=(xt-(self.sqrt_one_minus_alpha_cum_prod[t]*noise_pred))/self.sqrt_alpha_cum_prod[t]
x0=torch.clamp(x0,-1.,1.)
mean=xt-((self.betas[t]*noise_pred) / (self.sqrt_one_minus_alpha_cum_prod[t]))
mean=mean/torch.sqrt(self.alphas[t])
if (t==0).sum()==0 :
return mean,x0
else:
variance = (self.one_minus_alpha_cum_prod[t-1]) / (self.one_minus_alpha_cum_prod[t])
variance = variance * (self.betas[t])
sigma = variance ** 0.5
z = torch.randn_like(xt)
return mean+sigma*z, x0그 다음으로 diffusion 과정을 수행할 모델 UNet을 만들어준다.
class BlockU1(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,bias=False):
super(BlockU1, self).__init__()
self.attention=AttentionBlock(group=8,out_channels=in_channels,num_heads=8)
self.block1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.GroupNorm(8,out_channels),
nn.AvgPool2d(2),
)
def forward(self, x):
x = self.block1(x)
return x
class BlockU2(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,bias=False):
super(BlockU2, self).__init__()
self.attention=AttentionBlock(group=8,out_channels=in_channels,num_heads=8)
self.block1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.GroupNorm(8,out_channels),
nn.UpsamplingBilinear2d(scale_factor=2),
)
def forward(self, x):
x = self.block1(x)
return x
class UNet(nn.Module):
def __init__(self,concat_channel=0):
super(UNet, self).__init__()
self.block1=BlockU1(64+concat_channel,128)
self.block2=BlockU1(128,128)
self.block3=BlockU2(128,128)
self.block4=BlockU2(128,64)
def forward(self,x,condition=None):
if(condition is not None):
x=torch.cat((x,condition),dim=1)
x=self.block1(x)
x=self.block2(x)
x=self.block3(x)
x=self.block4(x)
return x최종적으로 stable diffusion model은 다음과 같이 만들어진다.
class StableDiffusion(nn.Module):
def __init__(self,concat_channel=0):
super(StableDiffusion, self).__init__()
self.time_schdule=TimeSchdule()
self.vae=VAE()
self.unet=UNet(concat_channel=concat_channel)
try:
self.vae.load_state_dict(torch.load('/content/drive/MyDrive/My_Models/stable_diffusion_vae.pt',map_location=device))
print("vae loaded")
except:
pass
self.encoder=self.vae.encoder
self.decoder=self.vae.decoder
try:
self.unet.load_state_dict(torch.load('/content/drive/MyDrive/My_Models/stable_diffusion_unet.pt',map_location=device))
print("unet loaded")
except:
print("no model")
def forward(self,x,noise,t,text=None):
z,mu,logvar=self.encoder(x)
z=self.time_schdule.add_noise(z,noise,t)
if(text is not None):
noise_pred=self.unet(z,text)
z,z0=self.time_schdule.sample_prev_timestep(z,noise_pred,t[0])
else:
noise_pred=self.unet(z)
z,z0=self.time_schdule.sample_prev_timestep(z,noise_pred,t[0])
output0=self.decoder(z0)
output=self.decoder(z)
return output,output0학습과정은 다음과 같다.
traindataset=datasets.ImageFolder(root="/content/drive/MyDrive/transparent",transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize((512,512))
])) #당신의 이미지 데이터셋을 넣으세요
traindataset=torch.utils.data.DataLoader(traindataset,batch_size=32,shuffle=True)
vae=VAE()
unet=UNet()
try:
vae.load_state_dict(torch.load('/content/drive/MyDrive/My_Models/stable_diffusion_vae.pt',map_location=device))
unet.load_state_dict(torch.load('/content/drive/MyDrive/My_Models/stable_diffusion_unet.pt',map_location=device))
print("model loaded")
except:
print("model load failed")
vae.train()
unet.train()
vae.to(device)
unet.to(device)
time_schdule=TimeSchdule()
optimizer_vae=optim.Adam(vae.parameters(),lr=1e-4)
optimizer_unet=optim.Adam(unet.parameters(),lr=1e-4)
criterion=nn.MSELoss()
for epoch in range(100):
for i,(image,_) in enumerate(traindataset):
if(image.shape[0]!=32):
continue
image=image.to(device)
noise=torch.randn(32,64,512//16,512//16).to(device)
t=torch.randint(0,1000,(32,)).to(device)
#optimize vae
optimizer_vae.zero_grad()
vae.train()
output,mu,logvar=vae(image)
loss_vae=criterion(output,image)
loss_vae.backward()
optimizer_vae.step()
#optimize unet
optimizer_unet.zero_grad()
vae.eval()
z,mu,logvar=vae.encoder(image)
z=time_schdule.add_noise(z,noise,t)
noise_pred=unet(z)
loss_unet=criterion(noise_pred,noise)
loss_unet.backward()
optimizer_unet.step()
if(i%100==0):
with torch.inference_mode():
print("epoch:",epoch,"batch:",i,"loss vae:",loss_vae.item(),"loss unet:",loss_unet.item())
z,mu,logvar=vae.encoder(image)
noise_pred=unet(z)
z,z0=time_schdule.sample_prev_timestep(z,noise_pred,t)
output=vae.decoder(z0)
torchvision.utils.save_image(output,f"/content/output_{epoch}_{i}.png")
torch.save(vae.state_dict(),'/content/drive/MyDrive/My_Models/stable_diffusion_vae.pt')
torch.save(unet.state_dict(),'/content/drive/MyDrive/My_Models/stable_diffusion_unet.pt')몇번의 epoch를 수행하면 다음과

같은 이미지들을 생성할 수 있고 학습이 된다는 것을 알 수 있다.
더 좋은 사전학습된 vae를 쓰면 더 빨리 좋은 결과를 얻을 수 있다.
아마 더 학습하면 더 좋은 퀄리티의 이미지를 만들 수 있을것이다.
'클라우드 > colab' 카테고리의 다른 글
| Colab을 이용해 인공지능을 개발해보자!-4편: xtts를 활용하여 무료로 자신만의 AI Voice 생성하기 (0) | 2024.06.08 |
|---|---|
| Colab을 이용해 인공지능을 개발해보자!-3편: PyTorch 텐서 조작하기 (0) | 2024.05.23 |
| Colab을 이용해 인공지능을 개발해보자!-2편: PyTorch란? (0) | 2024.05.23 |
| Colab을 이용해 인공지능을 개발해보자!-1편: Colab이란? (0) | 2024.05.15 |



